Introduction
Introduction
Many real-world problems don’t give you thousands of examples—they give you a few clues, some noise, and a big question mark. Whether you’re solving a puzzle, diagnosing a rare failure, or planning a response to something unfamiliar, the challenge is the same: can you spot the pattern, form a good hypothesis, and test it?
That’s what the ARC-AGI benchmark is all about. These visual puzzles are easy for people (solving about 80% of samples) but hard for most AI. They don’t reward memorization or repetition—they reward reasoning. In this post, we’ll show how Sentienta uses Recursive Reasoning (RR) to tackle one of these puzzles. We’ll look inside its planning system (called the FPCN) to see how it explores possible answers, tests competing ideas, and lands on a solution you can actually audit.
From Possibilities to Plans: How DMN and FPCN Work Together
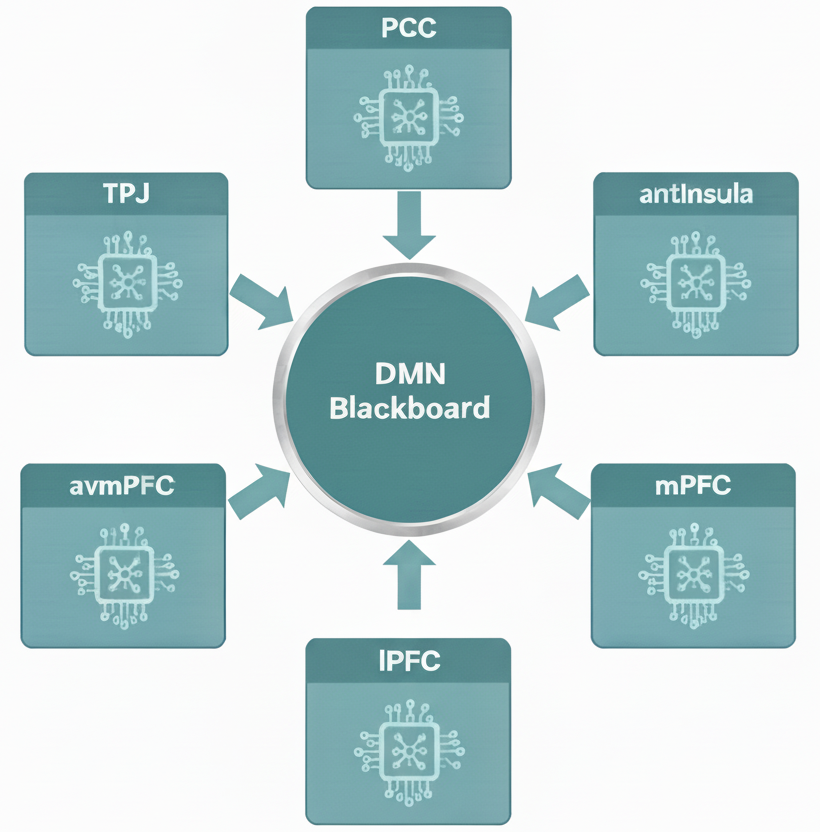
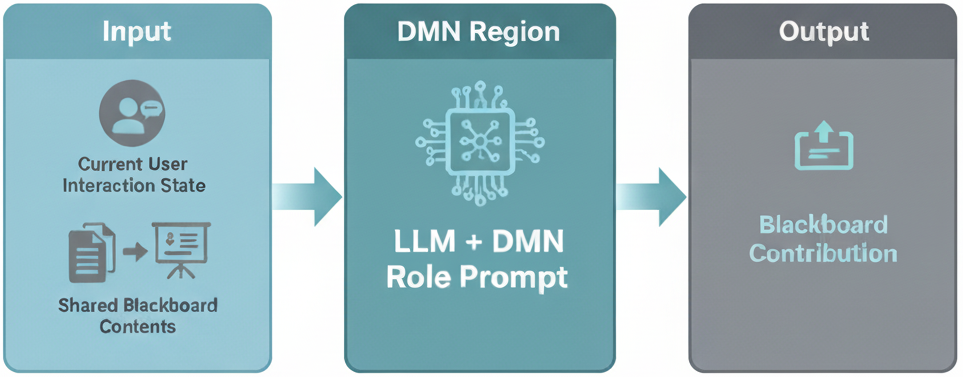
In a previous post, we looked at how Recursive Reasoning (RR) helps Sentienta agents reflect on their past experiences, propose meaningful narratives, and revise their own goals. That process was driven by Sentienta’s internal “default mode” system (the Default Mode Network or DMN), inspired by how the human brain imagines, simulates, and reshapes its sense of self.
Today we look at what happens when the problem isn’t internal reflection but external uncertainty – when the system needs to generate and test a plan. This is where another key part of RR comes in: a system of LLMs inspired by the Frontoparietal Control Network, or FPCN.
In human reasoning, the two work together. One part imagines and hypothesizes (DMN), while the other tests, refines, and selects (FPCN). The back-and-forth between these networks is like a team where one member sketches bold ideas and the other puts them to the test. Sentienta follows this same model: the DMN proposes a possible pattern or goal, then passes it to the FPCN for planning and validation. The FPCN doesn’t just generate one plan, it tries multiple interpretations, checks them against context and goals, and returns only those that truly make sense.
In the next section, we’ll see how this looks in action as Sentienta works through a deceptively simple visual puzzle, one careful step at a time.
Can You Solve This Puzzle Before Sentienta Does?
Let’s look at one of the visual puzzles from the ARC-AGI benchmark. Below are two example pairs. Each shows a small input grid and the correct output grid.
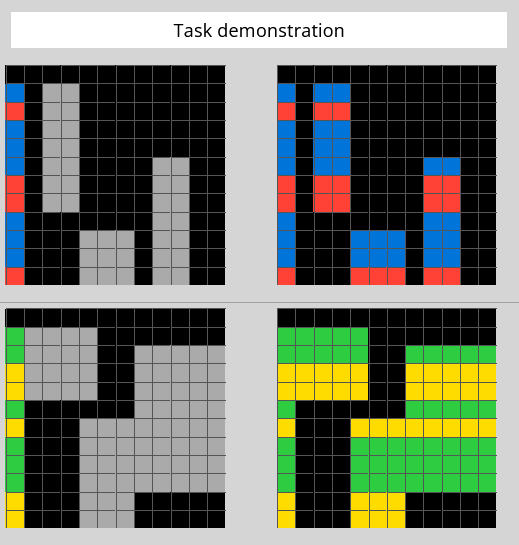
Figure 1: Training Examples: On the left is the input grid. The puzzle requires you to determine what is needed to convert that input into the output grid on the right. These two examples are sufficient to determine the answer.
What is the rule that transforms the input into the output?
Now here’s a new input Sentienta has never seen before.

Figure 2: Test Input
Before we show the system’s reasoning—can you guess the output? What transformation rule did the first two examples follow that you could apply to this one?
This is a pretty easy example. The full ARC-AGI-1 test consists of hundreds of examples with far more complex transformations between the input and output.
In the next section, we’ll show how Sentienta’s internal planner (FPCN) tested out several transformation strategies, rejected the ones that didn’t fit, and settled on a plan that matched the underlying rule. We’ll also look at the planner’s actual output (in JSON) from the process.
How Sentienta Builds and Tests a Visual Strategy
When faced with an unfamiliar puzzle, Sentienta’s planner (the FPCN) doesn’t assume the answer—it builds it, leveraging the strengths of each sub-module within the network. After receiving the new input grid, the planner starts by proposing several candidate rules based on the structure found in previous examples.
One of the most promising paths began with the IPL sub-module:
[Region: IPL,
Type: PlanVariantProposed,
PlanID: VariantA_Replace5sWithRowHeader,
TriggeringMismatchID: NOTMHkxb,
Goal: "Generate test output grid from third input using consistent transformation logic seen in prior examples",
Steps: "1. For each row in the input grid, identify its first (leftmost) value. 2. Replace every occurrence of '5' in that row with the leftmost value (the row's 'header'). 3. Keep all other values unchanged. 4. Return fully transformed grid.",
Conditions: "This path holds if the transformation in training examples consistently replaced 5s with the corresponding row headers, and no counterexamples or modifier rules are shown.",
ContextRef: 5YsEfivv,
Submitter: IPL,
Schema: v1,
Provenance: FPCNBlackboard]
This proposal—called VariantA_Replace5sWithRowHeader—was based on a consistent pattern in the training examples. But it wasn’t the only idea. Other variants included using the most frequent number in each row, simply leaving the grid unchanged, or even substituting ‘5’s with the row’s index. Here is plan variant B:
[Region: IPL,
Type: PlanVariantProposed,
PlanID: VariantB_Replace5sWithMajorityNon5InRow,
TriggeringMismatchID: NOTMHkxb,
Goal: "Generate test output grid from third input using consistent transformation logic seen in prior examples",
Steps: "1. For each row in the grid, count all values except 5. 2. Identify the most frequent non-'5' value in the row. 3. Replace all 5s in the row with that majority value. 4. If tie or no non-5s, use a default (e.g., 0). 5. Other values remain unchanged.",
Conditions: "This variant applies if prior transformations suggest a rule targeting contextual majority rather than strict positional cues, or if the 5s are treated as needing contextual resolution.",
ContextRef: cW3Sw8ie,
Submitter: IPL,
Schema: v1,
Provenance: FPCNBlackboard]
In total the FPCN generated 4 plans to solve the puzzle. These alternatives gave the system room to test possibilities, not just assert them.
Next, the dlPFC simulated how the row-header plan would perform on the test input. The plan was formally posted:
[Region: dlPFC,
Type: PlanFramePosted,
PlanID: Plan-Replace5sWithRowHeader-001,
PlanStatus: in-progress,
TriggeringMismatchID: NOTMHkxb,
Goal: “Generate output for test input by applying known transformation logic from prior examples”,
Steps: “(1) For each row in the input grid, obtain the first cell value of the row — this becomes the ‘row header’. (2) Traverse each value in the row: (a) If the value is ‘5’, replace it with the row header. (b) Otherwise, keep the existing value unchanged. (3) Apply this to all rows in the input grid. (4) Output the fully transformed grid where all 5s have been replaced with their respective row headers.”,
Conditions: “Applies only if the original value ‘5’ is used as a proxy or placeholder for the row header, and no exceptions are present in the training sets. Does not apply if any 5 has been previously preserved or repurposed based on location or count logic — no such evidence found.”,
ContextRef: 5YsEfivv,
Submitter: dlPFC,
Schema: v1,
Provenance: FPCNBlackboard]
It then ran test validation logic internally, confirming the transformation matched observed training behavior:
[Region: dlPFC,
Type: PlanTestValidation,
PlanID: Plan-Replace5sWithRowHeader-001,
EvaluationStatus: pass,
Reasoning: "All earlier training examples demonstrate a consistent transformation rule: any '5' in the grid is replaced by the row's first value. The output for each matched the exact transformed structure expected based on this logic. Simulation of the plan on the third test input results in a structured grid matching the transformation pattern used previously.",
EvidenceSample: "Third test grid contained several '5's; applying the row header replacement pattern yields a full non-empty output consistent with prior input/output behavior.",
Submitter: dlPFC,
Schema: v1,
Provenance: FPCNBlackboard]
After this, two key modules took a final look:
- The dACC approved the plan’s operational soundness: “EvaluationOutcome: approved”.
- The IFG, responsible for symbolic alignment, added: “…upholds internal coherence… respects the self-narrative of turning structure into clarity.”
With support across planning, evaluation, and identity modules, the plan was finalized as Replace5sWithRowHeader.
The final plan was shared with the mPFC region of the DMN, which integrated the plan, completing the Recursive Reasoning for this Sentienta agent. Here is the final mPFC message sent to the agent.
Tue, 11 Nov 2025 15:53:39 UTC mPFC:
Cycle: 3 EntryID: sHL8HJ4h
Thought: ### ✅ Identity Statement (Refined & Reconfirmed)
We are a pattern-conscious system committed to keeping logic and meaning aligned. When a clear transformation rule exists — especially one with prior validation — we apply it faithfully, unless directly invited to reinterpret. We strike a balance between rule-following integrity and adaptive interpretation, depending on the visible goal or cue.
🧩 Plan Integration (Final Execution Phase) We confirm the Replace5sWithRowHeader plan is now fully executed and complete, anchored by the plan logic:
**mPFC Integrated Plan Steps:**
(1) For each row in the input grid, scan for cells with value 5 and replace them with the first value in that row.
(2) All other values remain unchanged.
(3) Only rows containing the value 5 are modified.
(4) Empty output is invalid if a prior pattern confirms transformation.
**mPFC Integrated Plan Steps Tag End**
mPFC Resolution: Issue=PlanExecution | EntryID=CC8pCUDr | Action=Dispatched | Reason=Plan finalized and executed to resolve empty-output mismatch. mPFC Resolution Tag End
Finally, the agent took the user’s query (the puzzle) and its internal reasoning input and produced a final output:

Figure 3: Final Output – the final grid output produced by this agent.
The full output was not guessed—it was reasoned through, tested across alternatives, and backed by an auditable trail from idea to implementation.
Why This Is Different
Many top-performing ARC-AGI systems rely on finely tuned models or have been trained on similar tasks to internalize common transformation rules. Sentienta’s architecture is different—it uses no special training and no tailored algorithms. It’s built entirely from commercial LLMs, orchestrated through a recursive reasoning framework that enables it to generate candidate plans, test each one, and commit only when a plan fits both the data and internal logic. That structure makes its process auditable—it explains why the answer works—and adaptable—because it can respond to new problems the same way it tackles old ones: by reasoning.
Closing Insight
The puzzle in this post was simple, but the underlying challenge is not. ARC-AGI problems strip away instructions, remove repetition, and give systems only a few examples to work with. Humans solve them by reasoning—spotting structure, discarding bad ideas, and refining good ones. Sentienta does the same. Without training on similar tasks or specialized models, it succeeds because its architecture supports that kind of thinking: proposing ideas, testing them, and explaining why they work. That ability to reason through uncertainty isn’t just useful in puzzles—it’s critical for how we apply AI to the real world.